Next Boost Pro 3.0 Chegou
Acelere seu
Potencial
A ferramenta definitiva para eliminar o Input Lag, otimizar o Windows e transformar seu PC em uma máquina de e-Sports.
CS2
VALORANT
ARC RAIDERS
FORTNITE
BATTLEFIELD 6
Arsenal Completo
Sinta a Diferença
Arraste para ver o impacto do Next Boost Pro 3.0
COM NEXT BOOST
SEM NEXT BOOST
Arraste para comparar o desempenho
Interface Next Gen
Visual clean, modo noturno nativo e usabilidade simplificada.
Preview
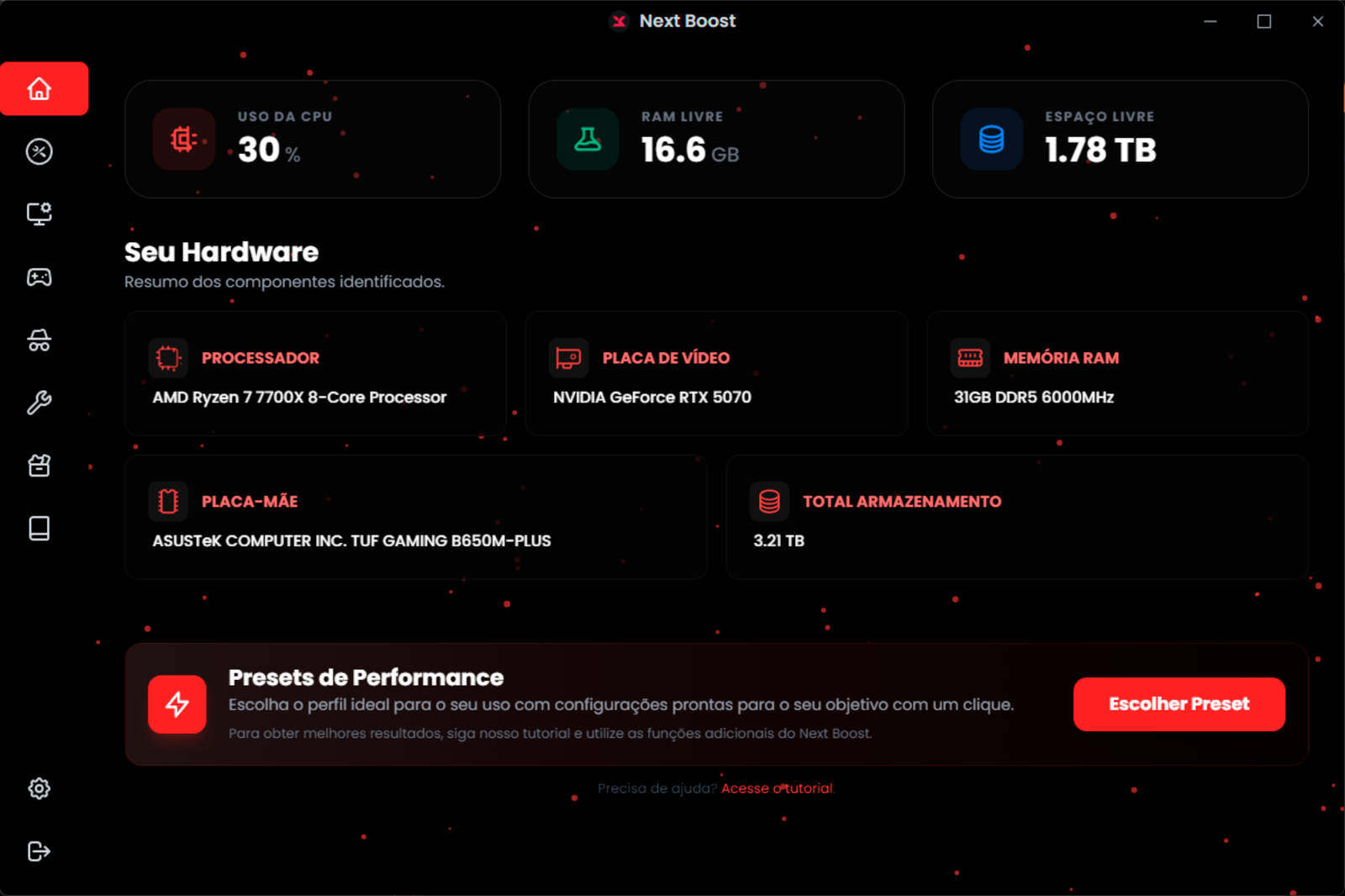
Central de Comando
Painel intuitivo com acesso rápido a todas as ferramentas de otimização.
Bônus Exclusivo
Manutenção Inclusa
Nosso app tem uma suíte de manutenção totalmente grátis.
Limpeza de Cache em 1-Click
Limpeza de Memória RAM
Modo Next Boost Ultimate Performance
🛠️
GRÁTIS HOJE
Valor: R$ 49,90
O que você recebe:
- ✔ Next Boost Pro 3.0 (Vitalício)
- ✔ Otimização Windows 10 & 11
- ✔ Script Anti-Lag Exclusivo
- ✔ Suíte de Manutenção Grátis
- ✔ Atualizações Futuras